By
Rohit Mittal Head of AI Products and Technologies
Santhosh K Thodupunoori, Director of Software Engineering
AI models have reached unprecedented sizes, far beyond the capacity of any single chip or even a single server. Building systems to train and serve these multi-trillion-parameter models is no longer just about making faster chips – it’s about architecting an entire rack as one cohesive “mega-accelerator.” In fact, modern AI infrastructure treats a rack of tightly interconnected accelerators as the fundamental unit of compute, essentially “one big GPU” at the rack level [1].
This post examines why chip-level and node-level designs are insufficient for AI models and highlights the importance of rack-level networking for the next generation of AI deployments. Furthermore, we dive into examples of ecosystems and technologies required to make rack-level networking feasible.
Why Chip-Level Design Falls Short for next AI models
We are witnessing exponential growth in model parameter scale (driven by Mixture of Experts, MoE) and an escalating reasoning scale (long context, complex tasks like Tree-of-Thought), both of which stress memory capacity and bandwidth more than raw FLOPs.
For example, a Mixture-of-Experts (MoE) version of GPT-4 was estimated at 1.8 trillion parameters requiring ~1.8 TB of memory **when running the model at FP8 [2]. These models must be partitioned across many accelerators, making inter-chip communication a bottleneck. In addition, LLMs processing long context windows (1M+ tokens) dramatically increase the KV cache size (64 kB/token/layer). A 128k context can mean 8GB KV cache per sequence/layer, quickly exceeding single-GPU HBM. Activation memory during training is also a challenge, managed by checkpointing or offloading, and more efficiently accessed across fast rack interconnects. Advanced reasoning (ToT, speculative decoding) multiplies memory demands, stressing capacity and bandwidth.
At a trillion-parameter scale, MoE models, while very efficient compared to dense counterparts, are highly communication-intensive. Inputs dynamically activate different experts that reside on different chips, requiring frequent inter-device messaging. This becomes a major performance constraint if interconnects are slow or lack bandwidth.
The Node: A Temporary Solution
The natural next step was the node: stuffing 8 GPUs into a server, hoping tighter integration would offset memory and bandwidth constraints.
It helped—but only up to a point. One analysis showed a 23% drop in throughput when a model was scaled beyond an 8-GPU server, due to interconnect limitations [3]. An H100 HGX, NVLink allows all 8 GPUs to talk to each other at 900 GB/s (bi-di) while communicating outside of a node would mean they can only communicate at 100 GB/s (bi-di) – much slower. Ethernet and InfiniBand couldn’t deliver the sub-microsecond latencies and high-throughput collective ops these models demanded.
When even the Node isn’t enough
The solution wasn’t to scale out—it was to redefine the compute boundary again and expand the 8-GPU scale-up domain to include more accelerators. Enter the rack. Systems like NVIDIA’s NVL72 treat 72 GPUs not as separate devices but as one coherent, memory-semantic machine with 130 TB/s of internal NVLink bandwidth. Physical constraints and emerging high-speed interconnects naturally converge at the rack scale—the largest domain where accelerators can effectively behave as a single, coherent computational entity before the complexities of distributed systems begin to dominate.
Table 1: Rack vs. Node/Chassis: Detailed Analytical Comparison for AI Workloads (2025 Outlook)
| Feature | Node / Chassis (4-8 Accelerators) | Rack (32-72+ Accelerators) | Rationale for Rack Superiority |
|---|---|---|---|
| Latency Budget (Intra-Unit Communication) | ~200 ns (On-board NVLink/PCIe) | ~300ns (Switched NVLink/UALink) [17] | Sub-µs latency across tens of GPUs in a rack is crucial for fine-grained parallelism in transformers (e.g., token dependencies, MoE routing), which cannot be sustained across multiple discrete nodes connected by slower networks. |
| Aggregate Bandwidth Density (Interconnect) | Limited by direct GPU-GPU links or PCIe backplane (e.g., 8×1.8 TB/s NVLink 5 theoretical max, but all-to-all constrained) | Extremely high via switched fabric (e.g., GB200 NVL72: 130 TB/s; UALink scalable) [18] | Rack-level switches provide vastly superior bisection bandwidth for the all-to-all communication patterns common in large model training (e.g., MoE expert communication, large gradient exchanges), which would saturate inter-node links. |
| Memory Coherence & Capacity (Scope & Scale) | CPU-GPU coherency (e.g., Grace Hopper 8); limited shared HBM pool. | Rack-scale coherent/near-coherent memory domain target (UALink, NVLink Fusion ); 8-16+ TB aggregate HBM. [13, 18] | Rack-scale fabrics with memory semantics allow a much larger pool of HBM to be treated as a unified address space, essential for holding massive model states (weights, KV cache, activations) that far exceed single-node capacity. |
| Power Envelope & Cooling Feasibility (at Scale) | 6-12 kW; air-cooling often feasible but stressed. | 90-140+ kW ; liquid cooling essential (direct-to-chip, CDUs ). [13] | Racks integrate power and liquid cooling for extreme densities unachievable by aggregating air-cooled nodes, making them the only viable physical unit for concentrating such compute power. |
| Physical Deployability & Serviceability | Individual server integration; complex cabling and power for many units. | Pre-integrated, modular designs (e.g., MGX ); standardized unit of deployment. [21] | Rack-level pre-integration and modularity drastically reduce deployment time and complexity compared to piecemeal node integration, improving TCO and operational efficiency. |
| Software/Scheduling Complexity (Large Models) | Frameworks must manage inter-node communication explicitly if scaling beyond node. | Target for “single system image” for frameworks; NUMA-like domain simplifies scheduling within rack. | Rack HBDs provide a near-uniform, low-latency environment that simplifies distributed training software (e.g., FSDP, Megatron-LM ) and improves its efficiency. |
| Failure Domain & Resiliency | Smaller individual failure domain. | Larger failure domain, but with rack-level redundancy in power/cooling. | While a rack is a larger fault domain, integrated management and redundancy at the rack level can be more robust and easier to orchestrate than managing failures across many independent nodes. |
| Economic Unit (Procurement, TCO) | Component-level procurement. | System-level procurement, financing, and depreciation. [20] | AI infrastructure is financed and deployed at the rack level. TCO benefits from density, power/cooling efficiency, and deployment velocity of integrated racks. |
NVIDIA NVL72: Rack-Scale AI via NVLink networking
NVIDIA’s NVL72 embodies this shift as it demonstrates a rack-level design by combining 72 Blackwell GPUs into a single high-performance rack interconnected via NVLink [4]. This architecture provides:
- 130 TB/s aggregate NVLink bandwidth [4]
- 900 GB/s per-GPU one-way bandwidth [4]
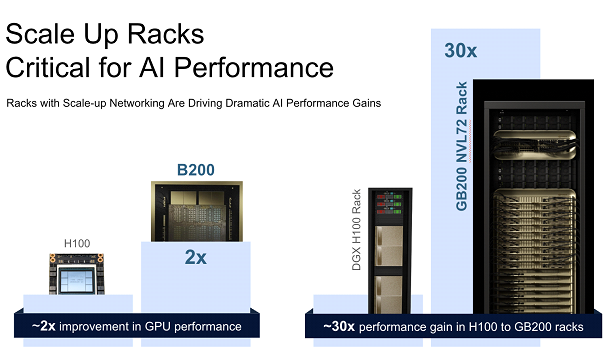
- 30x performance on trillion-parameter models compared to InfiniBand-connected H100s and changing from FP8 to FP4 [4]
Analysis by Nvidia shows the improvement scale-up rack provides over raw chip performance gains. Note – exact performance improvement number may vary based on assumptions on workloads, baseline etc.
Sources:
NVIDIA Blackwell Doubles LLM Training Performance in MLPerf Training v4.1 [24, 25]
NVIDIA GB200 NVL72 performance [26, 27]
Each NVL72 rack consumes ~120 kW and delivers up to 1.4 exaFLOPS of AI throughput (FP4) [5]. The system is liquid-cooled, weighs ~3,000 lbs, and integrates 5,184 passive copper lanes for connectivity [6]. Google’s TPU v5p “cube” (a rack equivalent with 64 chips in a 3D Torus) demonstrates a similar rack-scale building block.
This approach of using scale up networking transforms the rack into a supercomputer, with ultra-low latency switching/routing and massive internal bandwidth enabling collective operations, remote memory access, and dynamic parallelism.
Scale-Up Networking Requirements
AI models demand the following networking properties:
- Ultra-low latency: Accelerator to accelerator <200 ns per hop. Ethernet and standard networks are too slow [7].
- High bandwidth: > 10TB/s per node. NVLink provides ~900 GB/s; PCIe Gen5 tops at ~32 GB/s [4][8].
- RDMA and memory semantics: To treat remote memory as local with minimal overhead [9].
- Efficient collectives: All-reduce, broadcast, and scatter-gather must be hardware-accelerated or topology-aware [10].
- Scalability: Ability to connect 100s to 1000s of GPUs within one logical fabric [11].
To realize these requirements, there is an urgent need to invest in ecosystems and technologies. Below are examples of both ecosystems, along with the technologies required for the next generation of AI networking.
Ecosystem: UALink – Scale-Up Fabric for the Rack
The UALink Consortium recently introduced UALink: an open standard for scale-up networking [12].
Key Specs:
- 200 Gbps per lane, scalable up to 800 Gbps bidirectional per port **with 4 lanes per port ** [13]
- <1 μs round-trip latency for 64B messages [13]
- Scales to 1,024 accelerators across 4 racks [13]
- Ethernet-based PHY to reduce cost and leverage commodity components [13]
By standardizing a high-radix, low-latency memory-semantic fabric, UALink can democratize rack-scale AI systems.
One often-overlooked enabler of rack-scale coherence is memory semantics—the ability for accelerators to access peer memory with load/store/atomic operations. This is not just a hardware optimization; it’s an ecosystem shift.
As detailed in our previous blog [22], memory semantics reduce reliance on RDMA stacks and allow peer GPU memory to be accessed like local HBM. This flattens software complexity, increases efficiency for small transactions (<640B), and enables a new generation of AI frameworks to treat a rack as one logical memory domain.
Importantly, UALink institutionalizes memory semantics as an open standard. Previously, only proprietary stacks like NVLink or Google’s ICI supported these semantics. UALink opens the door for multi-vendor ecosystems to converge on memory-coherent fabrics, without locking into a single vendor.
In that sense, memory semantics aren’t just a protocol detail—they are the core abstraction around which the future rack-scale AI ecosystem is being built.
Technology: Rack-Level Networking
Rack-scale systems need advanced networking technologies:
- Cabled backplanes, like in NVL72, allow dense copper interconnects with better signal integrity [6]
- Active midplanes, like NVIDIA’s Kyber project, simplify assembly and cooling [15]
- Next generation packaging and connectors such as NPC (near packaged copper), CPC (co-packaged copper) and CPO (co-packaged optics)
Investments are needed to ensure these new technologies can be manufactured in high volume with adequate quality and low cost for hyperscale deployment.
The second architectural shift is in the topology itself. As we shared before [23], switch-based interconnects are now the baseline technology for scaling beyond 8–16 GPUs.
Compared to direct mesh, switches[23]:
- Scale linearly with node count (vs O(N²) link explosion)
- Enable in-network collective offloads (e.g., AllReduce in switch hardware)
- Simplify vPod creation and dynamic partitioning for multi-tenant inference
- Improve cable management and signal integrity through tiered leaf-spine topologies
These aren’t just theoretical advantages—they are what make architectures like NVL72 or future UALink-based racks feasible. It’s the minimum requirement for treating a rack as one coherent compute fabric. Without switched interconnects, rack-scale AI collapses under its own complexity.
Conclusion: The Rack Is the New Compute Atom
For large AI models, the rack is the only unit large and fast enough to behave like a coherent compute substrate. Rack-level design enables memory-semantic interconnects, extreme bandwidth, and model-scale parallelism.
As models grow beyond 1 trillion parameters, optimizing within the boundaries of a rack becomes crucial for minimizing latency and maximizing throughput. In this world, it’s not just about chip design—it’s about how the chips and interconnects are co-engineered at rack scale. To enable this a vibrant ecosystem and investment into new technologies are crucial.
AI engineers should begin thinking in racks: designing model parallelism and dataflow to stay within high-speed rack fabrics, optimizing memory layouts for RDMA, and architecting clusters as groups of smart, modular racks.
The rack is the unit of AI.
Bibliography
- NVIDIA GTC 2024 Keynote – Jensen Huang. – https://www.nvidia.com/en-us/gtc/
- SemiAnalysis: The Trillion Parameter Push – GPT-4 MoE. – https://www.semianalysis.com/p/the-trillion-parameter-push-gpt-4
- MLPerf Training v3.1 Benchmarks. – https://mlcommons.org/en/inference-datacenter-31/
- NVIDIA DGX GB200 NVL72 Overview. – https://www.nvidia.com/en-us/data-center/dgx-nvl72/
- ServeTheHome: Hands-on with NVL72. – https://www.servethehome.com/nvidia-dgx-gb200-nvl72-hands-on/
- ServeTheHome: NVLink Backplane Design. – https://www.servethehome.com/nvidia-dgx-gb200-nvl72-hands-on/
- HPCwire: Latency Challenges in AI Networks. – https://www.hpcwire.com/2024/05/09/scale-up-ai-networks-nvlink-ualink-and-ethernet/
- PCIe Gen5 and Ethernet Performance Comparison. – https://www.anandtech.com/show/17410/pcie-gen5-bandwidth
- AMD Infinity Fabric Overview. – https://www.amd.com/en/technologies/infinity-fabric
- NCCL: NVIDIA Collective Communications Library. – https://developer.nvidia.com/nccl
- UALink Consortium Whitepaper. – https://www.ualink.org
- The Next Platform: UALink Challenges NVLink. – https://www.nextplatform.com/2024/04/29/amd-intel-and-their-friends-challenge-nvidia-with-ualink/
- UALink 1.0 Specification. – https://ualinkconsortium.org/wp-content/uploads/2025/04/UALink-1.0-Specification-PR_FINAL.pdf
- ServeTheHome: UALink vs Ethernet vs NVLink – Power and Cost. – https://www.servethehome.com/amd-intel-and-their-friends-ualink/
- NVIDIA Kyber Midplane System Preview. – https://www.servethehome.com/nvidia-rubin-kyber-platform-preview/
- Open Compute Project: Rubin Platform Contributions. – https://www.opencompute.org/projects/nvidia
- UALink has Nvidia’s NVLink in the crosshairs. – https://www.tomshardware.com/tech-industry/ualink-has-nvidias-nvlink-in-the-crosshairs-final-specs-support-up-to-1-024-gpus-with-200-gt-s-bandwidth
- NVIDIA GB200 NVL72 – AI server. – https://aiserver.eu/product/nvidia-gb200-nvl72/
- Enabling 1 MW IT racks and liquid cooling at OCP EMEA Summit | Google Cloud Blog, accessed June 2, 2025. – https://cloud.google.com/blog/topics/systems/enabling-1-mw-it-racks-and-liquid-cooling-at-ocp-emea-summit
- White Paper: Redesigning the Data Center for AI Workloads – Raritan. – https://www.raritan.com/landing/redesigning-data-center-for-ai-workloads-white-paper/thanks
- Building the Modular Foundation for AI Factories with NVIDIA MGX. – https://developer.nvidia.com/blog/building-the-modular-foundation-for-ai-factories-with-nvidia-mgx/
- Why scale up needs memory semantics – https://auradine.com/why-scale-up-needs-memory-semantics/
- Communications within a high bandwidth domain pod – https://auradine.com/communications-within-a-high-bandwidth-domain-pod-of-accelerators-gpus-mesh-vs-switched/
- B200 training performance – MLPerf 4.1 – https://developer.nvidia.com/blog/nvidia-blackwell-doubles-llm-training-performance-in-mlperf-training-v4-1
- Comparing NVIDIA Tensor Core GPUs – NVIDIA B200, B100, H200, H100, A100 – https://www.exxactcorp.com/blog/hpc/comparing-nvidia-tensor-core-gpus
- Nvidia GB200 NVL72 – https://www.nvidia.com/en-us/data-center/gb200-nvl72
- NVIDIA GB200 NVL72 Delivers Trillion-Parameter LLM Training and Real-Time Inference – https://developer.nvidia.com/blog/nvidia-gb200-nvl72-delivers-trillion-parameter-llm-training-and-real-time-inference