Introduction
AI infrastructure is scaling at an incredibly fast pace in the cloud and the edge data centers for both training and inference. Large AI/ML models with hundreds of billions to several trillions of parameters need multiple Accelerators (GPUs) to train and run. Multiple Accelerators allow their training to be completed in weeks and months instead of years. Also, multiple Accelerators allow these models to respond to queries (inferencing) in less than a second instead of in tens of seconds or minutes. However, when the models are trained and run on multiple Accelerators, an extremely high-performance scale-up network is required to interconnect these Accelerators as they often need to exchange hundreds of megabytes of data, for example, to synchronize their partially trained parameters, to pass on partial computation results to the Accelerators to the next model layer, etc. According to this technical blog, “A single query to Llama 3.1 70B (8K input tokens and 256 output tokens) requires that up to 20 GB of TP synchronization data be transferred from each GPU. “ Transmitting 20GB on the wire at 200Gbps link speed takes 0.8s, and at 1.6Tbps, it takes 0.1s. This transmission time is by far the largest component of the total transfer time, which includes the propagation time, which is approximately 7ns for 2m of cable distance, and scale-up switch latency of approximately 100-200ns. Hence, the amount of network bandwidth available to each GPU is an important factor in reducing training or inference time.
Today, the Accelerators in a high-bandwidth scale-up domain are connected via a proprietary point-to-point mesh or switched topologies. Examples of mesh or partial mesh topologies, where the links are mostly based on PCIe specification, include Infinity link (AMD), Inter-Chip-Interconnect (ICI, Google), NVLink (Nvidia), and NeuronLink (AWS). For a switched topology, Nvidia’s NVLink switch is the only option today. While both these connectivity options are in use today, we believe that the industry will shift to a switch-based topology once standard-based multi-vendor scale-up switch solutions are available.
A switched topology connecting the Accelerators in a scale-up high-bandwidth domain (HBD) not only provides higher bandwidth, it also provides multiple other benefits compared to a full or partial mesh (e.g., toroid) topology with direct Accelerator-to-accelerator connections. These benefits are described below. There are some advantages in full or partial mesh topologies which are discussed towards the end of this blog.
A. Advantages of switched topology
A.1. Bandwidth Advantage
Let’s consider a scale-up domain with N Accelerators, where each Accelerator has N-1 times K GBps of egress bandwidth and N-1 times K GBps of ingress bandwidth. In a full mesh topology a given Accelerator (e.g., Accelerator 1) is connected to each of the other N-1 Accelerators at K GBps (see Fig.1). In a switched topology, all this (N-1) x K GBps of bandwidth to and from Accelerator 1 is connected to one or more switches (see Fig. 2). Hence, if Accelerator 1 wants to read memory attached to Accelerator 2, it can do so at K GBps in a full mesh topology and at (N-1) x K GBps in switched topology! In a scale-up domain of just eight Accelerators that is 7 times faster in a switched topology compared to a full-mesh topology (see Fig 2).

In 3-dimensional toroid topology, each Accelerator is typically connected to six immediate neighbors, two each in x, y, and z directions with point-to-point links. In such a topology also, Accelerator 1 can read memory attached to Accelerator 2 at 1/6th the bandwidth compared to a switched topology.
A.2. Pod Size Advantage
The number of Accelerator to Accelerator connections in a full mesh topology grows at the rate of the square of the number of Accelerators! For example, to grow a pod from 8 Accelerators to 16 will require 4 times the number of inter-Accelerator connections from 56 (8 x 7) to 240 (16×15) connections. With this rate of growth, it quickly becomes impractical to implement larger, fully-meshed Pods due to challenges in cable management and signal integrity. For example, inferencing in the 1.8T MOE GPT model requires connectivity between 72 Accelerators to fit the model in the combined memory capacity. This would be impractical with a full mesh of 72 Accelerators requiring O(N^2) links.
With a switched topology, the connectivity growth is linear. For example, in a Pod with N Accelerators, there are N connections, one from each Accelerator to a switch.
In a switched topology, the switch also acts as signal regenerators or “retimers” between the accelerators and hence provides a longer physical reach between them. This helps in building a larger Pod with cost and power efficient copper cables.
An even bigger Pod can be built using a second or Spine layer of switches that connects the first or the Leaf switches, as shown in Fig. 5.

The Leaf switches and their directly connected Accelerators can be housed in one rack connected via passive copper cables. The Spine switches are used to connect the leaf switches in different racks using active copper or fiber cables, depending on the Pod size.
A.3. Collective Operations Completion Time Advantage
AllReduce is the most commonly used collective operation in ML training jobs. It is typically executed in a logical Ring topology where each Accelerator passes on partially reduced data to its immediate neighbor in a clockwise or anticlockwise direction in the ring (see Fig. 3). In a direct full-mesh topology while Accelerator 1 transfers AllReduce data to Accelerator 2 only the connection from Accelerator 1 and Accelerator 2 is used. All connections to other Accelerators from Accelerator 1 are unused. Whereas in a switched topology, Accelerator 1 can use its full bandwidth to transfer data to Accelerator 2 without interfering with Accelerator 2 transferring its own partial AllReduce data to Accelerator 3, and so on. With N-1 times more bandwidth available from Accelerator 1 to 2 in a switched topology, the ring AllReduce operation will complete N-1 times faster compared to direct full mesh topology! For example, if each Accelerator has 15 high-speed links to 15 Accelerators, the switched fabric can effectively offer 15 times the bandwidth for ring reductions compared to a full-mesh network and 6 times more than a 3-D torus partial mesh. This substantial increase in bandwidth directly accelerates the collective communication step, enabling more efficient distributed training.
A.4. In Network Collective Advantage
Certain collectives, such as Broadcast and AllReduce, can be executed more efficiently if they are offloaded to the network. For example, when AllReduce is executed in the switch, each accelerator needs to transfer the data to be reduced once to the switch, and the switch transfers the reduced data to the accelerators. Whereas in ring AllReduce, each accelerator will need to send partial data multiple times to its ring neighbor. With a directly connected partial or full mesh topology in the network collective operation is simply not possible.

A.5. Flexible vPod Topology Advantage
AI/ML infrastructure providers rent Accelerators to multiple tenants on demand. In order to accommodate multiple tenants or workloads of different compute requirements, infrastructure providers need to carve out a subset of Accelerators in a virtual Pod or vPod for each tenant. These Accelerators need to have high bandwidth between them as they are working together on the same AI/ML workload. On the other hand, these Accelerators don’t communicate at all with the rest of the Accelerators. A switched topology providing any-to-any one-hop low-latency connectivity is much more flexible for creating vPods compared to a partial mesh network that involves a multi-hop higher latency connectivity pattern. Furthermore, such partial mesh topologies require that all the accelerators in a vPod be close to each other; otherwise, traffic between two accelerators of a tenant has to traverse through an Accelerator belonging to another tenant (see Fig. 4).
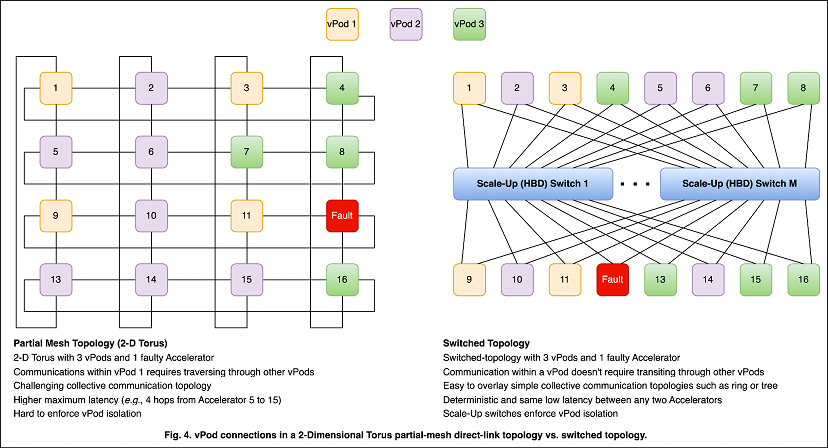
This not only creates an unacceptable security risk but also constrains vPod sizes, complicates the AllReduce topology, and requires the sharing of links between vPods. If AllReduce operations in two vPods happen to overlap in time, then both the AllReduce operations will take even longer to complete.
For inference jobs, the number of Accelerators needs to be dynamically increased or decreased depending on the inference request rate. A switched topology provides a much more granular and flexible autoscaling capability compared to a mesh topology.
In order to protect against the switch being a single point of failure, multiple switch planes are deployed. For example, Fig. 4 shows a switched topology with M switch planes. This allows quick reconfiguration of a Pod with a spare Accelerator to work around Accelerator or link failures.
B. Advantages of mesh topology
The biggest advantage of a mesh topology is cost since no switch is required. For a small Pod (e.g., 4-8 Accelerators), latency is another advantage in full mesh topology since no switch hop is required. Power consumption is harder to compare since, in mesh topologies, the data has to be forwarded via multiple Accelerators, and each of those steps consumes energy.
Summary
It is useful to remember that local computer networks started without switches. For example, once popular, Token Ring and CSMA/CD networks didn’t have any switches. In these networks, compute nodes were directly connected to their immediate peers or to a shared transmission medium via a hub. For example, in the early days, processors in Cray supercomputers were interconnected in a 3D Torus topology (T3D). Then came the Ethernet Switch in the 1990s. Once Ethernet switches became widely available, the industry quickly recognized the benefits and moved to switched topologies. Today, processors in Cray supercomputers are connected over Dragonfly-based switched topology called Slingshot, which scales up to 250K endpoints with a maximum of 4 switch hops. A smaller network diameter reduces average and maximum latency, variations in latency, power requirements, and cost.
An extremely high-performance scale-up network is essential to support rapidly increasing AI/ML model size, inferencing workloads, token generation rates, and frequent model tuning with real-time data. Once such switch-based solutions are available from multiple vendors to interconnect the Accelerators in a scale-up high-bandwidth domain, Auradine believes that industry will quickly adopt them over mesh topologies – for their superior performance, technical merits, ease of operation and manageability, and security compliance. Most importantly, a standard-based scale-up networking solution from multiple vendors, such as Auradine, will ensure vendor optionality and interoperability, which will drive down the cost.
By: Subrata Banerjee, VP Software Engineering, AI Network, Auradine Inc.
Created: Feb 17, 2025; Last updated: Feb 20, 2025