Scale-up and Memory Semantics
The quest for building ever more powerful AI systems inevitably leads us to the challenge of scale-up networking. Efficiently networking GPUs and scaling them effectively is paramount to achieving high performance. In this blog, we’ll unravel the requirements of scale-up, demonstrate how memory semantics revolutionizes its impact, and examine various scale-up approaches.
Scale-up is the way we connect GPUs within a few server racks or pods, and as established in [3], switched connections provide superior bandwidth compared to point-to-point mesh networks. A quick look into GPU instruction sets reveals it can be broadly classified into ALU operations, data movement operations, and conditionals. Memory semantics defines the basic data movement operations of Read and Write, and while it can encompass more complex operations, we’ll focus on the essentials. This keeps the communication layer lean and fast, allowing more sophisticated logic to be managed at the application level.
Key metrics for good scale-up
The ultimate vision for scale-up is to present a single, unified system of high-TFLOP compute and enormous memory. The reality is far more intricate, involving numerous discrete GPUs linked by a web of network switches, NICs, and both copper and fiber optic connections. Through intelligent data movement libraries, we strive to create a cohesive memory space across these distributed components. Despite the inherent parallelism of AI workloads, which reduces the immediate necessity for GPU coherency, having coherent memory offers a slight advantage in simplifying the software layer.
Here are a few traits necessary for a good scale-up network architecture:
-
Low Latency
GPUs shouldn’t see a prohibitive penalty of accessing peer HBM vs local HBM. If you look at the hierarchical memory sub-system in a GPU, the latency can be in the range of 20-350ns and in the range of 140-350ns if we miss the first level cache. Providing a scale-up solution within these latency bounds, the lower the better, is reasonable.
![Figure 1: H100 memory access Latency [5]](/wp-content/uploads/2025/03/1.png)
Figure 1: H100 memory access Latency [5]
- High Bandwidth
Just to lay the context, two of the prominent GPUs have the following:
- MI300x has 5.3TB/s memory bandwidth while only 1TB/s peak IO bandwidth
- GB200 has 8TB/s per GPU memory bandwidth while only 1.8TB/s per GPU NVLink bandwidth
While achieving parity between memory bandwidth and I/O bandwidth may be impractical, a distributed memory system benefits significantly from high-bandwidth access to peer memory. Consider this: with each model parameter at 32-bit precision requiring 4 bytes, a 1.8-trillion-parameter GPT-4 model needs 7.04 TB of GPU RAM for loading alone. Training such a model requires even more memory to store optimizer states, gradients, and activations. Since individual GPUs typically have only a few hundred gigabytes of dedicated memory, accessing peer GPU memory is essential. Point-to-point connections limit bandwidth, whereas a switched, fully connected backplane offers full bi-directional throughput between any GPUs, maximizing data access.
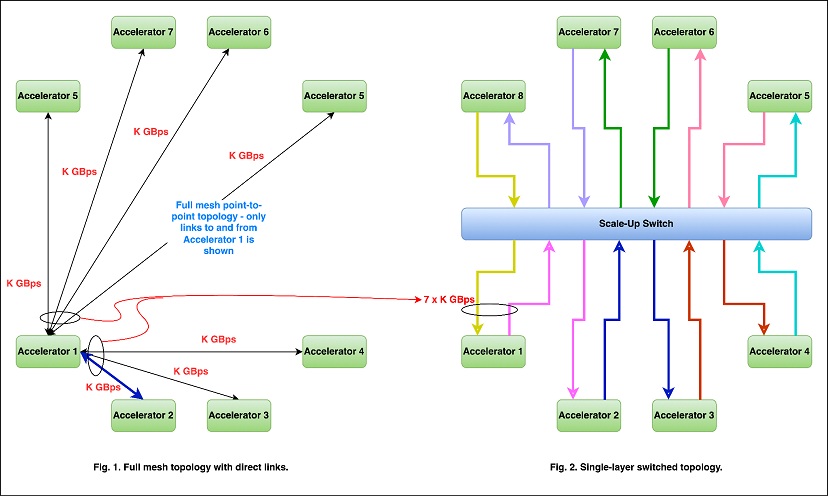
Figure 2: Point to Point Vs Switched Architecture
This comparison of various network architectures is well explained in this article [3].
- Low Total Cost of Ownership (TCO)
As the number of components grows and signal paths lengthen, the cost in terms of energy, silicon, and wiring escalates. Therefore, to present a practical unified memory abstraction, the number of additional switches, retimers, and cables must be kept to a minimum. This approach yields substantial cost savings in components and significantly reduces the rack’s power budget. This is a practical, albeit less technical, metric that is essential for judging the merit of a scale-up solution.
Memory Semantics helps in scale-up
Memory semantics drastically reduce latency by enabling direct memory transactions without the overhead of packing/unpacking or setting up RDMA. This simplification leads to leaner networking switches and a more efficient software stack, further contributing to lower latency. Since local HBM access times are now comparable to peer memory accesses, these transactions flow seamlessly, creating the illusion of a single accelerator with unified shared memory. This contrasts sharply with using Ethernet packets, which introduce significant latency through packing-unpacking, the RDMA stack, header parsing, and congestion management.
Efficient handling of small transactions is vital for optimizing AI model performance across distributed systems. Collectives within Tensor and Data Parallelism rely on the communication of small messages, typically between 32B and 640B. Likewise, Activation and Gradient exchanges in Pipeline Parallelism demand the rapid delivery of small, critical data. Consequently, irrespective of the parallelism method employed, the efficiency of small data communication has a substantial impact on overall performance. Echoing this sentiment, paper [6] states, “Even though DL models such as LLMs operate using massive message sizes, optimizations at smaller message sizes should be treated as equally important.”
The table below shows the distribution of communication of different sizes during the AllGather phase of three different GPT-NeoX models run on AMD MI250 system connecting two 8 GPU Pods.
| Datasize (bytes) | 19M Model | 1.3B Model | 13B Model |
|---|---|---|---|
| <640 | 74.82% | 59.91% | 39.49% |
| 1K-1M | 23.77% | 22.78% | 14.19% |
| 1-10M | 1.41% | 14.43% | 18.94% |
| 10-125M | 0.00% | 2.89% | 27.38% |
Table 1: Data Size Distribution in AllGather phase [6]
As illustrated in Table 1, a significant portion, between 40-75%, of AllGather communications involves transactions smaller than 640B. Our analysis of Llama3b training reveals that approximately 15% of all AI workload communication comprises these small-size memory transactions. These transactions are particularly prevalent during the training’s embedding and collective phases, such as AllReduce. Similarly, in Inference, the critical synchronization between layers relies on small transactions, impacting Job Completion Time (JCT). Leveraging a low-latency link for these small transactions can substantially improve JCT for both inference and training. While software techniques exist to mitigate latency, they often add complexity, necessitate large local buffers, or result in degraded performance.
With memory semantics, smaller transactions achieve line-rate transmission while ensuring both lossless and full-bandwidth utilization. This advantage extends to full-mesh traffic, where all transactions benefit from enhanced bandwidth regardless of size. Pairing memory semantics with full bi-directional bandwidth switches minimizes the performance hit of accessing peer memory.
Additionally, in-network collectives become simpler to offload with memory semantics, freeing up compute resources. Simplifying switch operations by avoiding deep header parsing and excessive buffering leads to a more efficient scale-up, resulting in lower power consumption and reduced die area, which ultimately contributes to cost savings and improved TCO through denser racks. In essence, memory semantics provide the low latency, high bandwidth, and optimized TCO that are essential for an effective scale-up architecture.
Possible solutions for scale-up networking
Now that we have established how memory semantics aids effective scaleup solutions let’s explore the scaleup options available in the market- NVLink, UALink, and proprietary custom protocols.
NVLink [2] is Nvidia’s proprietary scale-up solution that has helped Nvidia bring innovative solutions with a huge number of accelerators. NVL72 and NVL576 [4] would not have been possible without this key innovation that started in 2016.
UALink [1] is a new open standard that enables other accelerator vendors to avail the benefits of memory semantics for optimized systems that can scale up to 1024 nodes. This was opened to the public in October 2024, and its 1.0 Spec release is due to be released in April 2025.
Without a standardized solution like UALink, accelerator vendors resorted to creating their own scaling technologies, including Google ICI, AWS Neuronlink, and AMD InfinityFabric. These proprietary protocols, typically built upon PCIe or Ethernet, enabled interconnection but often catered to very specific infrastructure setups. While detailed information on these protocols is limited, it’s reasonable to assume their narrow scope limits broader applicability. For example, employing lossless Ethernet for AI, while beneficial for reliability, can result in inefficient bandwidth usage for small data packets and increased latency and power usage for larger ones. Moreover, PCIe’s physical layer technology trails Ethernet in terms of achievable bandwidth.
Conclusion
Scale-up is essential for creating a unified memory view across distributed accelerators, and memory semantics is the key to making this solution truly effective for AI workloads. While NVLink and UALink both present viable options, UALink stands out as the only open standard that supports memory semantics. Proprietary solutions, like Google’s ICI, may suffice for specific data centers but fall short for general AI workloads. The growing industry-wide support for UALink presents a critical opportunity for companies like Auradine to tackle the pressing scale-up challenges in AI infrastructure.
References
- https://www.ualinkconsortium.org/
- https://www.naddod.com/blog/nvidia-gb200-interconnect-architecture-analysis-nvlink-infiniband-and-future-trends?srsltid=AfmBOoouq6ANk8t6Q0t27ClA-iBrFY05ftCA162fsJFms-VmCrkAnCgg
- https://auradine.com/communications-within-a-high-bandwidth-domain-pod-of-accelerators-gpus-mesh-vs-switched/
- https://semianalysis.substack.com/p/gb200-hardware-architecture-and-component?utm_source=post-email-title&publication_id=329241&post_id=146663528&utm_campaign=email-post-title&isFreemail=true&r=7nsat&triedRedirect=true
- https://jsmemtest.chipsandcheese.com/latencydata
- Demystifying the Communication Characteristics for Distributed Transformer Models by Q. Anthony, B. Michalowicz, J. Hatef, L. Xu, M. Abduljabbar, A. Shafi, H. Subramoni, and DK Panda , IEEE Hot Interconnects Symposium 2024, August 2024
- Generative AI on AWS: Building Context-Aware Multimodal Reasoning Applications by Fregly,Barth and Eigenbrode
By: Amit Srivastava, VP AI Silicon, Auradine Inc