Generative AI training and inference workloads are becoming increasingly complex, involving enormous datasets and requiring significant computational resources to generate, fine-tune, and deploy AI models. As major semiconductor companies (e.g., Nvidia, AMD, Intel) and hyperscalers (e.g., Google, Amazon, Microsoft) have been developing GPU and accelerator chips for these models, there is a critical need to address the network connectivity across these for high performance. This requires the GPU’s to communicate with each other in ‘memory coherent pods’ and across racks in AI datacenters with ultra-low latency and high bandwidth requirements.
To meet this demand, two primary networking architectures are playing a pivotal role: Scale-Up and Scale-Out networking. Scale-Up involves the short-distance networking fabric connecting GPUs, CPUs, and memory together. Scale-Out addresses the network connectivity across multiple GPU pods or racks to handle increased load and computing power collectively. This blog outlines the Scale-Up and Scale-Out networking including the emergence of open, standards-based network fabric to power the future growth of generative AI workloads.
Understanding Generative AI Workloads
Generative AI using large language models (LLMs), transformers, and image synthesis tools have a substantial demand for computational and data throughput. These models often require extensive data parallelism, meaning they need to be trained across numerous GPUs, TPUs, or specialized AI accelerators. This parallelism results in heavy traffic within data center networks, putting considerable pressure on the infrastructure to deliver high bandwidth, low latency, and reliable interconnectivity.
Networking Challenges:
- High Bandwidth Requirements: Generative AI models require rapid data transfer between various nodes within the network. As the model sizes grow, bandwidth demands increase significantly, straining existing networking solutions.
- Low Latency Needs: Training generative models involves constant data transfer, meaning that even slight latency increases can drastically impact training times and computational efficiency.
- Scalability and Flexibility: AI workloads scale rapidly, requiring networking infrastructure to be scalable and flexible to accommodate new resources or nodes.
- Interoperability: The network should support a wide range of hardware components to avoid vendor lock-in, which can impede scalability and increase operational costs.
Scale-Up Networking for Generative AI
Scale-Up networking improves the capacity of a single, high-performance computing node by adding more resources, such as CPUs, GPUs, or memory, within a single cluster. For generative AI, this approach allows outfitting powerful servers with additional GPUs or accelerators to handle the increased computational demand.
Needs of Scale-Up Networking:
- Ultra-low Latency: To concentrate computational power in a single node, Scale-Up networking must minimize latency (e.g., sub-500 nanoseconds) beyond what traditional ethernet-based networks based on packets offer versus continuous data streaming.
- High performance data transfer: While maintaining low latency, need to address key areas that impact the quality of the network. This includes minimizing aspects negatively impacting performance such as network ‘jitter’ (inconsistency in the time delay between data packets being sent and received) and ‘tail latency’ (small percentage of network requests that take significantly longer to complete than the average response time).
- Reduce costs by maximizing GPUs and AI accelerators in a pod: Currently the highest number of inter-connected GPUs in a pod ranges from 4-8 on the lower end and up to 72 on the higher end. Providing the ability to connect to 100’s of GPUs in a pod can reduce the GPU deployment costs while supporting larger LLM models.
Scale-Out Networking for Generative AI
Scale-out networking distributes workloads across multiple interconnected pods or racks in a Gen AI data center, providing a robust solution for scaling large generative AI models.
Needs of Scale-Out Networking:
- High Bandwidth: ability for large data loads to be shared across GPU pods and racks with high throughput. This allows the AI datacenter to be highly scalable as it involves adding additional racks to meet growing AI demands for training and inference.
- Load Balancing: Ability to distribute traffic evenly across multiple network nodes to prevent bottlenecks and ensure consistent performance.
- Flexibility in Resource Allocation: Allow different GPU racks to be assigned specific tasks or model portions, allowing for dynamic resource allocation based on real-time demand.
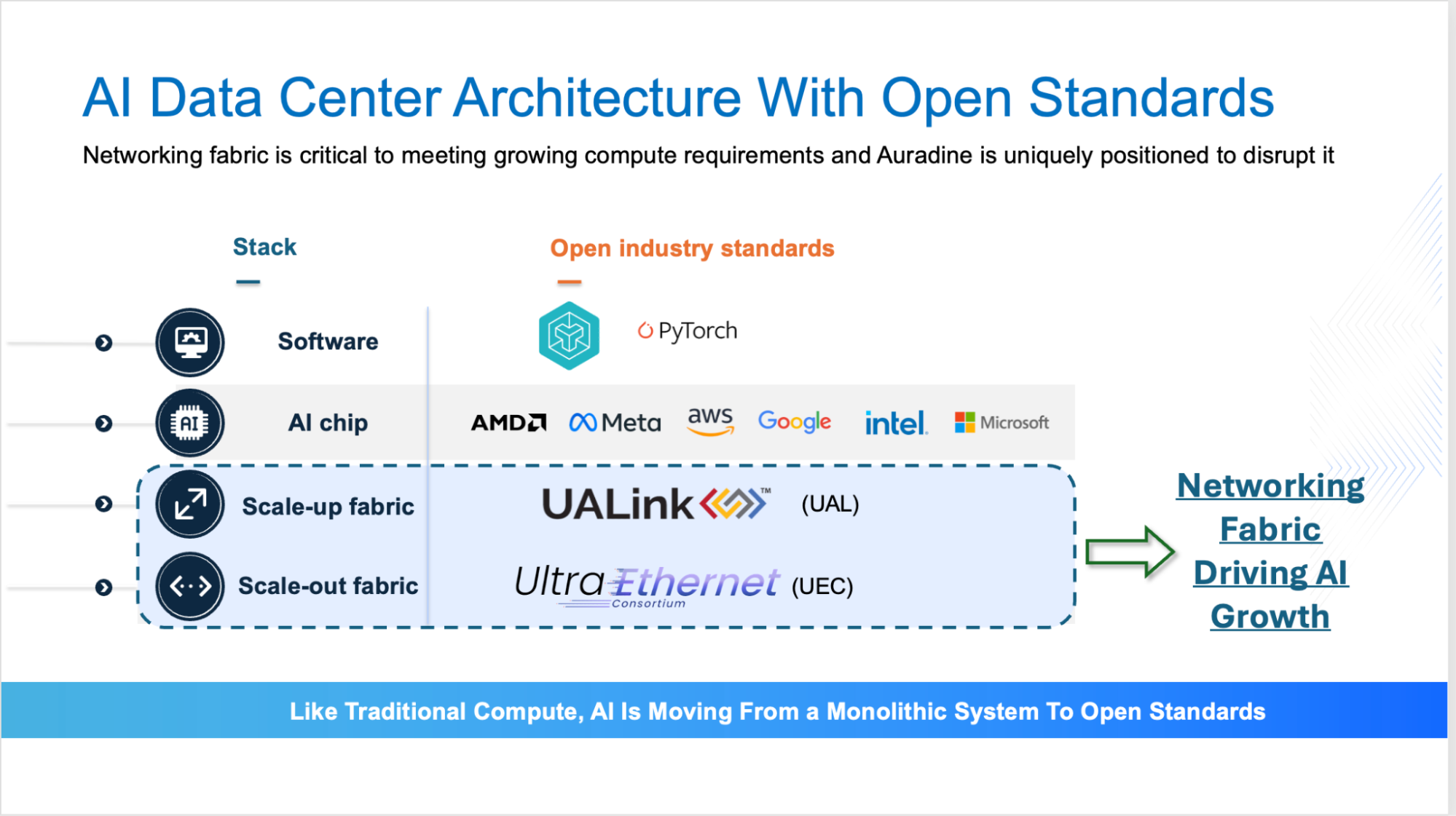
The Role of an Open, Standards-Based Network Fabric
An essential requirement in building a robust and scalable network infrastructure for generative AI workloads is the establishment of an open, standards-based network fabric. This allows collaboration across multiple players benefitting the industry as a whole versus proprietary stacks for individual companies. Towards this end, there have been two key industry consortiums that have been established in 2024 – the Ultra Ethernet Consortium for scale-out networking and Ultra Accelerator Link (UALink) Consortium for scale-up networking (diagram below). These include major industry players playing a key role in advancing the AI technology infrastructure and ecosystem.
Benefits of an Open Standards-Based Network Fabric:
- Interoperability: Open standards allow organizations to integrate diverse hardware components, including GPUs, CPUs, TPUs, and various accelerators, across different vendors. This flexibility helps avoid vendor lock-in and facilitates seamless expansion or upgrades.
- Cost Reduction: Proprietary hardware solutions often carry premium pricing. Open, standards-based fabrics enable organizations to adopt more cost-effective hardware without sacrificing performance, leading to more competitive pricing for high-performance networking solutions.
- Enhanced Innovation: Open standards foster collaboration and innovation within the industry, allowing multiple companies and institutions to contribute to network technology advances. This ecosystem promotes the development of new, more efficient solutions for generative AI workloads, creating alternatives to proprietary solutions like NVIDIA’s networking products.
- Future-Proofing: Open standards tend to evolve more rapidly in response to technological advancements, as they benefit from a larger developer and research community. By adopting a standards-based network fabric, organizations ensure that their infrastructure can adapt to emerging AI and networking innovations.
Looking Forward: The Future of Scale-Up and Scale-Out Networking
As generative AI workloads evolve, so will the need for scalable, high-performance networking infrastructures. An open, standards-based network fabric will not only serve as a feasible alternative to proprietary solutions. By adopting Scale-Up and Scale-Out networking architectures, organizations can build an adaptable, resilient infrastructure capable of meeting the demands of modern AI applications.
The establishment of Scale-Up and Scale-Out networking industry consortiums offers an ideal solution for handling generative AI workloads, balancing the need for high performance with scalability. Building an open, standards-based network fabric will be essential for fostering a competitive environment, driving down costs, and fueling innovation. Through these advancements, the field of generative AI can become more accessible, encouraging a diverse array of companies and institutions to contribute to and benefit from the AI revolution. In a rapidly evolving AI landscape, an open and inclusive approach to network infrastructure is strategic and necessary for long-term growth and sustainability.
- Sanjay Gupta, Chief Strategy Officer, Auradine